
There was a nice demo at the launch of Google’s new smartphone at the beginning of October, not for the smartphone itself, but for accompanying wireless earphones, called Pixel Buds. Pixel Buds tap into Google Translate to live translate conversations held in different languages – in the launch demo, a native English speaker conversed with a native Swedish speaker, each talking in their own language, with Pixel Buds translating what each person said into the other’s language. The earphones can understand 40 different languages.
This is something that really only Google can provide because of its existing Google Translate infrastructure. Google Translate has been the subject of some ridicule because of clunky translations, but the algorithm is learning all the time, especially since switching to the Google Neural Machine Translation (GNMT) neural network in November 2016 to improve the fluency of the service. The GNMT is able to translate sentences as a whole, rather than breaking up the sentence into words and phrases, resulting in a much more natural translation. It also has the advantage of a huge dataset to learn from.
The Google Neural Machine Translation network is a high-profile example of artificial intelligence developed by one of the companies at the forefront of the technology – the Google Brain team is behind the open source machine learning platform TensorFlow. Machine learning is not new, but neural networks have reached a point where everyone seems to be working on or taking about them, whether it’s for self-driving cars or face recognition – at the Embedded Vision Summit in May this year in Santa Clara, Jeff Bier, the founder of the Embedded Vision Alliance that organised the summit, said that 70 per cent of vision developers surveyed by the Alliance were using neural networks, a huge shift compared to only three years ago at the 2014 summit when hardly anyone was using them.
Now the technology is starting to filter down into the industrial vision market. MVTec’s Halcon vision library includes a deep learning OCR tool, and the version set to be released at the end of the year will have a more general deep learning classifier that can be trained for different industrial vision applications. Cognex has its Vidi deep learning software suite targeting the industrial vision market, while Adaptive Vision has released a deep learning tool within its Adaptive Vision Studio software.
Despite the activity in the industrial vision sector, the first thing to say is that conventional factory inspection tasks are not a natural fit for neural networks. ‘It will be difficult for deep learning to have immediate success in industrial vision, mainly because in an industrial environment or a production line machine vision is already successful enough,’ commented Dr Vassilis Tsagaris, CEO and co-founder of Greek embedded computer vision firm Irida Labs. The environmental parameters – lighting, angle of inspection, or distance of the camera from the object – can be controlled to a large extent in factory inspection, meaning traditional algorithms generally work well.
Johannes Hiltner, product manager for Halcon at MVTec Software, agreed that deep learning ‘will not revolutionise the machine vision industry’, while Michał Czardybon, general manager at Adaptive Vision, said that deep learning is not going to replace classical machine vision.
‘The first areas where deep learning will be adopted will be to solve problems where existing computer vision algorithms are not successful,’ Tsagaris continued. Irida Labs demonstrated an embedded device designed for food recognition at the Embedded Vision Europe (EVE) conference in Stuttgart, Germany from 12 to 13 October. The recognition was through its DeepAPI library for embedded devices that implement some of the most popular deep learning models like AlexNet or VGG. With this library Irida Labs can embed deep learning in different devices with standard CPUs or GPUs, according to Tsagaris.
The food recognition demo presented at EVE is a good example of an application where product recognition in an unconstrained environment is difficult using traditional algorithms. Another case is video analytics in surveillance – determining the gender and age of a person in real time. ‘Traditional algorithms limit the full adoption of such solutions,’ commented Tsagaris. ‘It’s not only the big drivers like automotive where deep learning can be used.’
Applications with lots of variation in the product or the environment are good candidates for deep learning, such as inspection of organic materials or webs of textiles. ‘A general idea of when deep learning might be useful is when you don’t have an exact idea of how to solve a problem,’ observed Hiltner. ‘As soon as you have different kinds of defects or different kinds of objects in the image, and you struggle with old algorithms to solve the classification problem, then it might be a good idea to look at deep learning. You just need to provide samples and the network automatically extracts the structures within the image.’
Halcon 17.12, which will be released at the end of the year, will provide a generic approach for deep learning applications. It will have a pre-trained network based on hundreds of thousands of images and optimised for typical industrial applications, which can be re-trained for a more specific application. The network is good for typical classification applications like defect detection or classification, such as distinguishing between good and bad circuit boards in the electronics industry.
Halcon 13 has a deep learning network optimised specifically for optical character recognition (OCR). It has a pre-trained network, highly optimised, based on hundreds of thousands of OCR samples. Results have shown that the deep learning classifier is twice as good as the conventional multi-layer perception (MLP) classifier – with a test data set of more than 80,000 industrial images, MLP gave an error rate of six per cent, while the deep learning classifier had three per cent error rate, Hiltner said.
To retrain the network in the deep learning feature of Halcon 17.12 for a customer-specific problem, first of all, the user needs to provide labelled sample data – 200 to 500 images are required for the class ‘good image’ and 200 to 500 samples for the class ‘defect image’. The system also needs a GPU, Hiltner noted, as the training process is calculation-intensive.
Hiltner remarked that the main benefit of deep learning is not necessarily a reduction in error rate, but the time and effort the customer saves for classifying the features that distinguish different classes. A manufacturer of glass products might see various different defects: a scratch, a bulb, a dent. All these defects look very different from each other. ‘Before deep learning, programmers would have to spend a lot of time finding algorithms or training old classifiers to distinguish a bulb from a scratch, for example,’ Hiltner said. ‘Now, with deep learning, you just provide the sample data of “defect class one” and the sample data from “defect class two”, and all the rest is done by the network automatically.’ The user therefore doesn’t need expert knowledge in order to program solutions to distinguish between classes; only sample data is required, which saves time.
Libraries like Halcon, Irida Labs’ DeepAPI, or Adaptive Vision Studio, which has recently released a deep learning add-on, are all designed to take some of the complexity out of neural networks. There are open source tools – Caffe and TensorFlow are two – but these require expert knowledge in machine learning and take many months to develop something that works for one particular application. Neural networks also require huge amounts of data, one of the reasons why they work best for tasks like Google Translate. Even for networks incorporated into Halcon or Adaptive Vision Studio, the more data that can be provided the more accurate the classification, although as the amount of data increases then so does the need for processing power from GPUs or FPGAs – Silicon Software’s Visual Applets graphic development environment now includes tools to implement neural networks on FPGA hardware.
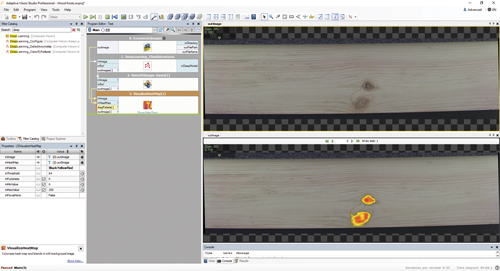
Neural networks are suited to identifying defects in organic materials like wood where there is a lot of variation between samples. (Image: Adaptive Vision)
‘Deep learning technology is complicated internally to a point that some say no one really understands it,’ commented Czardybon at Adaptive Vision. ‘However, this complexity is encapsulated inside tools available with modern machine vision software like Adaptive Vision Studio. What the vision engineer gets access to is simple and straightforward to use. The skills required are actually reduced compared to the standard machine vision tools.’
He continued: ‘Having said that, the style of work may change a lot and a different mindset might be required. Engineers, who used to create vision applications from functional blocks that were more or less possible to understand, now must switch to focus on labelling samples correctly and trying different combinations of learning parameters to achieve optimal performance. Some understanding of general machine learning concepts is highly recommended to make the process more systematic.’
Hiltner agreed that engineers will need to be able to handle data, but not necessarily algorithms. ‘In the next couple of years, we need to provide tools in order to label data rather than providing tools for programming algorithms,’ he said.
Tsagaris at Irida Labs added that the type of data is the most critical aspect rather than the amount of data. ‘You have to think like you’re teaching a child; you don’t only need to provide a lot of images, but images that are indicative of what is happening in the scene. This is the art of deep learning,’ he said.
The disadvantage of deep learning compared to conventional coded algorithms, however, according to Hiltner, is that if the network gives a wrong decision it’s nearly impossible to understand the exact reason for the discrepancy. ‘Engineers are problem solvers, so they want to get to the truth of the problem,’ he said.
Tsagaris believes that new types of engineer or scientists aren’t needed for deep learning. ‘People that work in machine learning are well equipped to succeed with deep learning; we have seen that in our team,’ he said.
‘The main questions engineers should ask themselves when investigating deep learning technologies are the performance needed and what platform should the application run on,’ Tsagaris advised. Irida Labs, which is coming from an embedded vision standpoint, can support a range of hardware prices and complexities, from Snapdragon 835 or 820 to a CPU or a Raspberry Pi. ‘Also, consider the frame rate required by the application, as you might not need to process at 30fps or 60fps,’ he added.
‘When you start to train the network and work with the data, knowing what the target platform is helps a lot. You don’t get carried away in complicated structures that might give you 0.5 per cent better accuracy that is really not needed in the application; it’s more about doing it in relatively low cost hardware,’ Tsagaris said.
In terms of the amount of data needed, this depends on the application. Developing a system for pedestrian detection in cars needs a huge amount of data that very few companies have access to, according to Tsagaris. In other cases, if there is a specific problem, Tsagaris said that it doesn’t cost too much development effort to work with the data. Cameras also might already be in place in some instances.
‘From an engineering perspective I don’t think deep learning is a cure for all diseases,’ Tsagaris remarked. ‘There is definitely room for what is already out there and working fine. For a computer vision engineer, deep learning is a new tool that has to be used together with everything else we know. Irida Labs works with a whole range of computer vision tools in its projects.’ Adaptive Vision Studio and Halcon are also incorporating deep learning as one tool among many other more traditional algorithms.
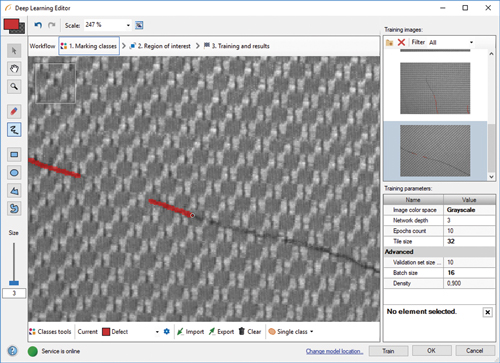
The data used to train the network needs to be properly labelled, with defects marked. (Image: Adaptive Vision)
Hiltner also made the point that deep learning does not solve all problems, saying that data code reading, localisation of objects based on contours, or 3D matching are all areas where deep learning is not considered of great benefit. ‘These will still be around in more conventional algorithms for the next 10 to 20 years,’ he said. ‘At the moment, we see deep learning as a powerful tool, but focusing on classification problems.’
Within the next couple of years MVTec will keep working on deep learning and will provide high-level interfaces, according to Hiltner. ‘We hope to improve the technology in such a way that our customers won’t need hundreds of samples per class, but only tens of samples per class,’ he said.
‘It’s still a young technology; it’s complex, but it’s absolutely worthwhile investing in, and this is what we’ll be doing over the next couple of years in order to make this complex technology available for a broader user range,’ Hiltner stated.
Tsagaris concluded: ‘The hype around deep learning creates a good environment to develop new imaging solutions in areas like machine vision or retail. If Tesla cars can detect pedestrians, then why can’t less complex imaging solutions be engineered with this technology? You then get new ideas to solve existing problems. The tools that Google or Nvidia develop and invest in for a big market like automotive will give us good opportunities in the machine vision field.’
