Deep learning has made waves in machine vision in recent years, both as a technology capable of improving existing vision solutions, while also providing a solution to difficult vision challenges.
The technology largely simplifies the creation of image processing algorithms. While in traditional machine vision a human is required to specify and evaluate specific image features to define the rules of an algorithm, with deep learning this can largely be automated.
By simply showing neural networks either as whole images or regions of images from a labelled dataset, they can learn which features are relevant for classification purposes and automatically define rules for image processing algorithms. These algorithms can then be deployed on smart cameras and used to identify such features on images.
Despite the promise deep learning has shown, however, it should be noted that the tool will not be a silver bullet for all vision challenges, rather another arrow in the vision integrator’s quiver.
This is because while some applications benefit greatly from deep learning – such as the classification of amorphous objects such as faces, food products, bacteria colonies or parcels – for many industrial applications, particularly those where conditions can be managed and objects are already known, traditional vision methods are often preferred. In some cases, cleverly combining deep learning with traditional methods may yield the best results.
Dozens of datasets
While having the potential to solve a great number of vision challenges, deep learning also introduces its own difficulties in that it creates a need to manage and label exceptionally large amounts of training data, which has been the cause of many headaches in past deep learning projects.
‘When you start working with deep learning you end up with dozens, if not hundreds, of datasets from different projects, and then multiple versions of each of these datasets,’ said Michał Czardybon, CEO of software firm Adaptive Vision. ‘Each of these has to be annotated when creating a deep learning model.
‘What makes things even more complicated is that when you have multiple people working on a number of different projects, it can be very challenging to keep everything in order and organised.
‘In addition, as the projects progress, customers continue to send in more batches of sample data, while also changing parameters between batches, such as lighting, lenses and location.
‘This creates an increasing amount of chaos and complexity when trying to keep track of everything.’
According to a study by Forbes in 2016, data scientists spend about 80 per cent of time on data management tasks, contrasted with four per cent on refining their algorithms. What’s more, the majority of the scientists reported data management to be the least enjoyable part of their work.
Thankfully, in recent years a number of software tools for efficient data management and labelling have emerged. Such tools enable time and effort to be saved during the management and labelling of training data for deep learning, which can ultimately lead to a lower cost of the resulting solution.
Online data management
For Adaptive Vision, the future of data management and labelling for deep learning projects is online.
Czardybon explained that traditionally many machine vision customers are accustomed to having all of their images on a disk drive, which are then shared within the company using a local shared computer with a big enough disk.
‘This can lead to issues with data management,’ he said. ‘Datasets end up being exchanged in an unco-ordinated way, which leads to confusion as to where the most up-to-date version of each dataset actually is, or which models are trained with which datasets.’
While a number of offline tools have emerged for data labelling for machine vision, Czardybon remarked that these are more suited to deep learning projects being developed by a single person controlling everything. For team-based projects, however, there is a need for more professional dataset sharing and co-ordinated image annotations.
‘One data labelling tool that has emerged for the general market in recent years is Labelbox, which is owned by several investment funds, including one from Google,’ he said. ‘There has been quite a bit of buzz around this tool as the whole process of data labelling has been moved online. We see this as a very disruptive feature, especially for a highly conservative industrial market such as machine vision.’
Adaptive Vision therefore bought the online data annotation platform Zillin in January, and has since invested heavily into its further development.
‘While Labelbox covers a wide range of general features for deep learning, our focus with Zillin is solely on machine vision,’ said Czardybon. ‘We have therefore focused on making it a very intuitive, easy-to-use tool for machine vision professionals for organising and annotating images.’
He explained that by moving data management and annotation online, the convenience of working with images for deep learning projects can be improved dramatically.
Rather than transferring images to and from the customer via physical storage devices such as USB drives (as used to be the norm for Adaptive Vision) with Zillin, image folders can be dragged and dropped into a common online workspace. A number of team members with varying levels of editing permissions can then be added to this space. ‘This helps us organise everything to a much higher standard,’ said Czardybon.
In addition, with online platforms such as Zillin, not only is the transfer of data between a firm and its customers now much simpler, but customers can continually be engaged throughout the training of the deep learning model.
‘The customer can see what you are annotating and even participate in this process,’ Czardybon confirmed. ‘This is a very important feature as annotations must be discussed. In fact, 95 per cent of projects that we’ve had ourselves in recent years have required discussion – “is this a defect or is it not?”. With Zillin you can call the customer and open and look at the same image, allowing you to confer with them, while annotating the data.’
Moving data online not only provides easier access to existing datasets, but also enables a history to be kept of the datasets that have been used to train a deep learning model, in addition to what has changed within these datasets.
‘Our market is adjusted to engineers who create a system and then deploy it. However, with deep learning we believe there will instead be an ongoing process of retraining the system whenever something changes,’ said Czardybon. ‘For that you will need to keep track of what datasets have already been used to train your deep learning model. Online is the perfect place to do this.’
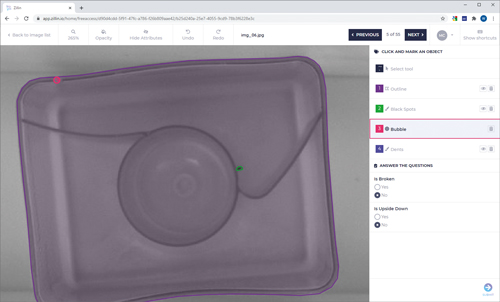
Adaptive Vision’s online platform Zillin simplifies the management and labelling of training data for deep learning. Credit: Adaptive Vision
Adaptive Vision is currently in the process of introducing end-to-end encryption to Zillin, which has proven to be a big requirement for many customers. ‘Maintaining the confidentiality of data has been the number-one issue our customers have had,’ said Czardybon. ‘This end-to-end encryption is still in early development. We hope for this to be a killer feature.’
Lessening the labour of labelling
The quality of a deep learning solution stands or falls with the quality of the data used to train it. While deep learning algorithms are capable of describing scenarios of unprecedented complexity, it is vital for the training data to represent the full variety of the application scenario. More complex scenarios require more complex and larger amounts of training data, which itself requires a greater effort to label.
‘Data is the oil of the 21st century. Like crude oil data must be analysed, filtered and processed very carefully before it can be used properly – otherwise it won’t work well and a certain loss in performance must be expected,’ said Christian Eckstein, product manager for MVTec Software’s deep learning tool.
‘Lastly, it’s always important to keep in mind that a deep learning network can only learn what it sees. Wrongly labelled or unlabelled data can significantly degrade the classification or detection results.’
The amount of data labelling required depends on the type of deep learning method used: supervised or unsupervised learning. Supervised methods require a relatively large amount of data labelling in order to teach the network, while unsupervised methods require little to no labelling.
In terms of applications, anomaly detection, for example, will only require good samples for training and only a few for testing – since it only evaluates the differences of an image relative to the average of the training images.
Most other applications, however, such as classification, object detection and semantic segmentation, will require large amounts of data to be labelled and managed.
‘Supervised learning, i.e. learning from data labelled by a subject matter expert, will typically produce by far the best results in terms of accuracy,’ explained Arnaud Lina, director of research and innovation at Matrox Imaging.
He advised that, to train, the source data needs to be split into different sets, and only the training dataset can have augmented data, since only authentic data can be used to evaluate the training process and validate the trained deep neural network. If the data augmentation strategy is not satisfactory, the augmented data can be deleted and newly generated.
Ideally, for the best training, Lina said that the data must be balanced. Each category must have the same amount of training data. However, one problem with using neural networks for industrial inspection is that manufacturing processes do not produce a lot of bad widgets, which makes the collection of such image data time consuming.
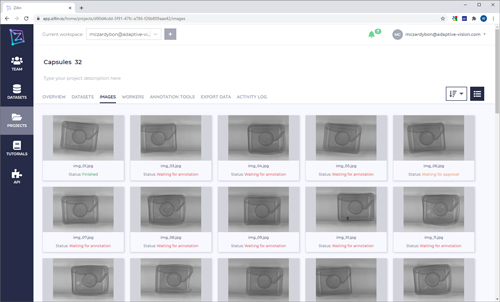
Zillin enables multiple users to co-ordinate when labelling images for training a deep learning mode. Credit: Adaptive Vision
Other challenges Lina noted include data labeling errors, whether due to an error during the data collection or because of ambiguous data. Biased data is also a problem, such as gathering good data under certain illumination conditions and bad data under different illumination, or performing data augmentation in a way that unknowingly shifts the classification problem. These are pitfalls to be avoided.
In the Matrox Imaging Library SDK, a dataset API is provided to simplify data manipulation – a sort of lean database specifically for deep learning. The API allows the user to retrieve all unlabelled images, as well as images associated with a specific category, augmented images, etc, and easily compare the ground truth with the predicted category. Also, MIL SKD includes its Copilot tool, which can be used to explore and prototype machine vision recipes, as well as generate functional program code. It now has the functionality needed to prepare for deep learning training.
Lina said: ‘The overall system must allow quick review of the source (data quality, augmented data and labelling) and the result of the training process to determine the corrective actions to undertake to improve the accuracy of the deep learning solution.’
Neural networks require large amounts of images in order to perform well, potentially in the tens or hundreds of thousands of images. Pretrained models, such as those included in MVTec’s deep learning tool, can bring this down to a few hundred images.
‘With our algorithms and pretrained networks we try to bring the number of images required for an acceptable result as low as possible,’ said Eckstein. ‘For the images that need to be labelled, we want to make the completely integrated workflow as smooth, transparent and efficient as possible.’
For a successful deep learning application, the whole data pipeline must be managed. This includes image acquisition, integration into the correct project and datasets, labelling, training, retraining and model management.
‘Most labelling solutions only support a subset of these aspects,’ noted Eckstein. ‘This is especially important, since deep learning data pipelines are not a linear but an iterative process, where data is continually collected, and the neural networks are improving over time.’
Before labelling, the key is to define the label classes well. Defect classes in industrial applications, for example, tend to be extremely hard to differentiate to non-experts – and even they may disagree in many cases.
‘The [labelling] tool should support this process, for example by displaying reference images to labellers,’ said Eckstein. ‘We have seen projects fail because of a small number of label errors in the dataset. The labelling tool should help find and remove those errors easily.’
With its deep learning tool, MVTec targets the improvement of efficiency when data labelling. ‘We measure the amount of time and user actions required for labelling specific test cases, and try to improve the workflow to shave off as many seconds as we can,’ Eckstein explained.
‘Another method is so-called bootstrapping, where the model is first trained on part of the dataset in order to make label suggestions. This can help about halfway through the process.’
For semantic segmentation, the network has to assign individual pixels to classes. Here, labelling is especially costly, according to Eckstein.
‘For this method, our research department has had promising results for segmentation methods that should cut down the labelling time by several factors,’ he said. ‘Since labelling effort has been holding this technology back, we hope that these new methods will facilitate a breakthrough in industrial applications.’
Lowering the barrier to entry
Imaging firm IDS has developed an online deep learning platform where image data can be uploaded, managed and labelled. Named IDS NXT Lighthouse, the solution is designed to lower the barrier of entry into deep learning by working with IDS’ Rio and Rome cameras and requiring no programming skills or an IT infrastructure, besides a PC, to operate.
The software, which is supported by Amazon Web Services, is included in IDS’ NXT Ocean package, which, the firm says, includes everything required to set up an inference camera for an application.
Ideally, training data is acquired in an application-related scenario by the same camera onto which the deep learning solution will be deployed. This helps to build a representative dataset. Oliver Senghaas, head of marketing at IDS, said: ‘For a simple good/bad decision a few tens or hundreds of images will suffice to train a first model. With the knowledge gained from frequent real-world evaluations, the dataset can be expanded step by step to meet the scenario’s requirements. Our goal is to make this improvement as quick and easy as possible.’