Artificial intelligence (AI) is beginning to infiltrate the machine vision world, just as it is in everyday life. The established industrial vision software firms, such as MVTec Software, Adaptive Vision and Matrox Imaging, are building neural network capabilities into their products, while firms specialising in deep learning and targeting industrial imaging are also springing up.
Deep learning technology is expected to be present in abundance at the upcoming Vision trade fair in Stuttgart, from 6 to 8 November. Among the regular exhibitors with software products – MVTec will run a two-hour seminar on deep learning at the show – there will be some new names on the exhibition floor: Sualab, a South Korean firm, which plans to unveil Suakit deep learning software for machine vision; Deepsense, an AI company based in Warsaw, Poland; and Portuguese inspection company Neadvance.
'Just a classifier'
Convolutional neural networks (CNNs) can outperform traditional algorithms – in some circumstances yielding impressive results – but not in all, or even the majority, of situations. ‘A neural network is not the Holy Grail,’ stated Johannes Hiltner, product manager for Halcon at MVTec Software. ‘It’s a great technology, but in the end, a neural network is just a classifier.’
Neural networks make decisions: is a part good or bad, or class ‘A’, ‘B’ or ‘C’? Dr Jon Vickers, from Stemmer Imaging, speaking at the UKIVA machine vision conference in Milton Keynes earlier in the year, noted that neural networks are good at tackling imaging problems where there is a lot of variation – inspecting organic material like fruit or wood, for example – and where a human would find it easier to show the machine the variation in images, rather than try and describe all those differences. A side effect of this, he noted, is that neural networks generally perform better than traditional algorithms with noisy images, or where there are occlusions.
Neural networks can ‘exceed our expectations and recognition rates of other classifiers, such as support vector machine (SVM)’, Hiltner observed. But for specific tasks, like locating objects very precisely in an image, making metric measurements, or reading barcodes, ‘traditional algorithms still outperform deep learning’.
‘Algorithms for locating an object based on edge extraction, operating at sub-pixel precision, have been refined over the years, and a neural network would never reach this level of precision or speed,’ Hiltner continued. ‘You need dedicated algorithms to measure angles or distances between two edges. These algorithms outperform deep learning by orders of magnitude.’
In most cases, machine vision tasks are solved by a combination of different algorithms, and deep learning is just part of the solution. There are few applications that can be solved in their entirety with only a neural network – one example is face detection. But industrial applications are more complex: first an image is acquired; then there’s pre-processing, then a measurement is made, and then the object might be inspected for quality. The quality inspection part can be solved with deep learning, but post-processing or extracting the measurements of a defect are best done with traditional algorithms.
In one of its projects, MVTec worked with a logistics customer. The task was to program autonomous vehicles in a warehouse to recognise whether high racks were empty – and could therefore have items dropped into them – or were already full. This is a simple classification problem with a lot of potential variety in the images: if a rack contains items there could be various possible shapes, colours and sizes. The system had to be efficient but also cover the variation.
The customer solved the application first without deep learning, using a 3D sensor to analyse whether the high rack was empty or not. This approach had an error rate of 2.5 per cent. MVTec trained a CNN with image data from a standard 2D camera and achieved an error rate of 0.3 per cent. The approach also reduced the cost of hardware – a 3D camera can cost around €3,000 while a 2D camera costs around €500 to €700, according to Hiltner
A second example is one of MVTec’s Japanese customers, which builds machines for automatic pill packaging. The machines produce thousands of pills per minute and defects can appear in various forms. ‘It’s hard to find a traditional algorithm that can differentiate between defects and required textures on the pills, like imprints or predetermined breaking points,’ said Hiltner.
For a long time, the customer solved this application with traditional algorithms; each time a new pill type was added to the line, an expensive machine vision engineer had to travel to the customer’s manufacturing site and spend several weeks programming new algorithms to include the new pill.
MVTec realised it could speed this process up by using labelled images showing different classes of defect to train a neural network. Hiltner explained: ‘We could significantly reduce the engineering time required for adding new defects or pill types, as well as reducing the cost of developing an algorithm to inspect specific pills.’
At the European Machine Vision Association’s business conference in Dubrovnik, Croatia, in June, Michał Czardybon, general manager of Adaptive Vision, demonstrated the possibilities of his company’s deep learning tools. Adaptive Vision has used deep learning on projects ranging from detecting cracks in photovoltaic panels, to satellite image segmentation and robotic pick-and-place applications. Its latest tool, Instance Segmentation, was released for the Automatica trade fair in Munich in June, and is designed with robot pick-and-place tasks in mind. It combines object location, classification and region detection, and has been shown to work in a logistics application where the robot is handling lots of different types of object and large changes in lighting. The tool is trained with sample images using masks; it can separate objects that are touching and even intersect objects, according to Czardybon.
Preparing for success
Training a CNN from scratch typically requires hundreds of thousands of images. This is a huge effort – not only in terms of acquiring that amount of images, but also labelling them. Training the network takes time, too.
Most machine vision software packages get around this problem, in the case of MVTec’s Halcon by providing two pre-trained neural networks that only need a few hundred images to fine-tune. This is called transfer learning. The basic network is trained by MVTec, and the customer then tunes it using a few hundred of their own labelled images.

Sushi boxes can contain a lot of variation, and inspecting them is best solved with deep learning. Credit: Adaptive Vision
A CNN consists of multiple layers that extract features relevant for distinguishing between classes. The first layers are important when it comes to general features, such as edges, colour or light changes – basic features that nearly all kinds of applications have in common. The last layers extract more detailed, application-specific features. It’s these last layers that are fine-tuned by the customer.
Both MVTec and Matrox Imaging suggest a few hundred images for their respective CNNs, while Adaptive Vision says 20 to 50 images for training. In general, however, the more images the better the results.
Halcon’s pre-trained CNNs are based on an in-house image dataset covering different industrial applications, including electronics, food and automotive, among others. The pre-trained network is optimised for industrial applications and is based on millions of images.
There are pre-trained, open source neural networks available, but they will typically be trained using everyday images, not industrial images. In some cases, the images used to train open source CNNs can be subject to copyright restrictions. A common image dataset, called ImageNet, consists of millions of images – most of which carry a disclaimer stating that the images can only be used for the purpose of research and not for commercial gain.
‘When our customers design an application for their customers, they have to make sure they don’t infringe any licence agreements,’ explained Hiltner. The networks MVTec supply have no copyright licence issues.
Of the two pre-trained networks Halcon offers, one is optimised for speed and the other for recognition rate. Most of the applications in the industrial machine vision market can be solved using the speed-optimised network, Hiltner said.
Work is still needed, however, to prepare images to train a CNN, even for a pre-trained network. Pierantonio Boriero, director, product management for Matrox Imaging, commented: ‘A fair quantity of carefully labelled images is needed to effectively train and validate a CNN for a given purpose. Not only does this need to be done initially, but also continuously, especially when new or unforeseen cases arise in a particular application, to maintain system accuracy.’
Matrox Imaging employs machine learning in one of its optical character recognition (OCR) tools. The company has also released a deep learning classification tool for the Matrox Imaging Library (MIL) 10 software development kit. The tool is able to run on a mainstream CPU – an Intel processor, for example – in millisecond timeframes. MVTec Halcon 18.05 also gives an optimised CNN inference for Intel-compatible x86 CPUs, offering runtimes of approximately 2ms.
Czardybon noted that one advantage – depending on your point of view – of training a neural network is that ‘it forces the customer to make up their mind about what is a defect and what is not’. He said during his presentation at the EMVA conference that one of the problems with applying deep learning is labelling images inconsistently. He advised to start by clearly defining test cases, and that any ambiguity must be resolved with the customer up front. The software doesn’t need programming – it’s one of the big benefits of deep learning – but to get the best results ‘the user must be aware that there is a training process that needs to be done correctly’, Czardybon commented.
Czardybon also spoke about an application where deep learning was used to map roads on satellite images. Here, the CNN wasn’t 100 per cent accurate, mainly because of tree cover confusing the neural network. He said that people might expect deep learning to work perfectly in this situation, and that this should be a lesson for industrial users: not to expect the impossible.
New kids on the block
One of companies exhibiting for the first time at Vision in Stuttgart this year will be South Korean firm Sualab. The company offers dedicated deep learning software, which can be applied to machine vision applications – Hanjun Kim, marketing manager at Sualab, noted the Suakit has been used by Samsung, LG, Panasonic, Nikon, Hitachi, Hanwha, and SK. ‘Some of these customers are already applying our solution to the mass production line, which demonstrates our level of technology,’ he noted.
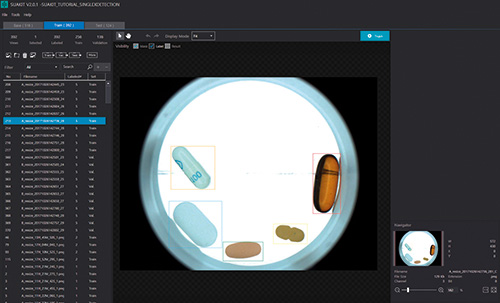
Automated pill inspection using Suakit deep learning software. Credit: Sualab
Suakit has three core functions that include segmentation, classification and detection. The segmentation function is for detecting defects; classification categorises defects into types, while the detection function can detect each target object in an image by class. Suakit uses a pre-trained network and Kim recommends at least 100 images of each defect type for training.
The Vision show will also have deep learning technology from Cognex on display, in the form of its VisionPro Vidi software. The tool can: locate and identify deformed features; separate anomalies and identify defects; classify texture and material; and perform demanding OCR applications.
However, deep learning still poses some challenges. Boriero at Matrox Imaging commented: ‘While the use of neural networks stands to accelerate and democratise the development of industrial imaging solutions and tackle inspection scenarios too ambiguous to resolve using traditional methods, it does pose significant challenges to users and suppliers of the technology. A balanced image dataset is needed to effectively train and validate a neural network for a specific categorisation job. Obtaining images of acceptable goods is much easier than of defective goods – especially when the latter comes in different occurrences that need to be tracked individually.
‘Users will need to embrace the process of acquiring and labelling images, not only for initial development, but also for future adaptation,’ he continued. ‘Providers on their end will need to better deal with unbalanced image datasets and simplify the training process for the user by, for example, cutting down on the trial-and-error approach to establishing the parameters for a successful neural network.’
Hiltner at MVTec concluded: ‘Deep learning will not be a game-changer. It will not revolutionise our industry, but it will enhance it in such a way that engineers who solve machine vision problems now might get to a solution quicker. They can use CNNs to quickly get an idea whether deep learning would solve their problem. Before that, engineers had to spend a lot of effort programming, testing, and optimising algorithms and inspection systems. Now, this is straightforward; just use some labelled images and see whether deep learning is a good enough approach or not.’
He added: ‘You can very quickly decide whether you are able to go on with a project using deep learning.’