")
Researchers from Japan have developed a new method for depth estimation using focus/defocus – the technique used to gauge the distance between objects using cameras – helping to overcome existing limitations.
The proposed technique, called ‘deep depth from focal stack’ (DDFS), has been outlined in the International Journal of Computer Vision, and was led by Yasuhiro Mukaigawa and Yuki Fujimura from Nara Institute of Science and Technology.
How does DDFS work?
Inspired by a strategy used in stereo vision, DDFS combines model-based depth estimation with a learning framework, establishing a ‘cost volume’ based on the camera settings, lens defocus model, and input from the focal stack where images are taken of the same scene from different distances.
Cost volume represents a set of depth hypotheses, including the potential depth values for each pixel, as well as an associated cost value calculated on the basis of consistency between images in the focal stack.
Yasuhiro Mukaigawa, researcher on the study, said: “The cost volume imposes a constraint between the defocus images and scene depth, serving as an intermediate representation that enables depth estimation with different camera settings at training and test times.”
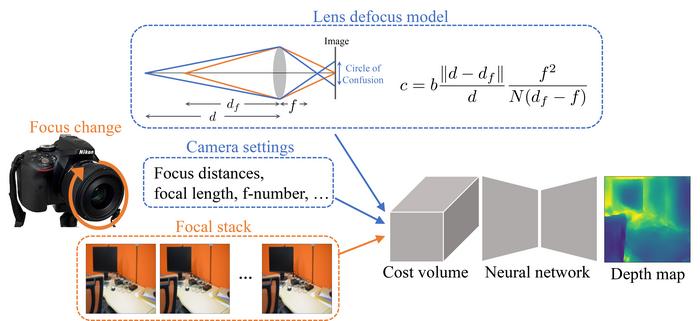
The proposed method takes input from the focal stack and camera settings, and establishes a cost volume based on a lens defocus model (Image: Yuki Fujimura)
DDFS also employs an encoder–decoder network, which estimates the scene depth progressively in a coarse-to-fine fashion. At each stage, DDFS uses ‘cost aggregation’ to help learn about localised structures in the images.
How does DDFS compare to existing methods?
When compared with other depth focus/defocus techniques, DDFS was able to outperform most methods across various metrics for several image datasets. Experiments also showed that DDFS could be useful with only a few input images in the input stacks, unlike other techniques.
Yasuhiro Mukaigawa added: “Our method with camera-setting invariance can help extend the applicability of learning-based depth estimation techniques.”
This allows DDFS to overcome the limitations associated with model-based methods, which use mathematical and optics models to estimate scene depth based on sharpness or blur, and learning-based methods, which can be trained to perform depth from focus/defocus efficiently, even for texture-less surfaces.
In doing so, it provides promise for applications where depth estimation is required, such as robotics, autonomous vehicles, 3D image reconstruction, virtual and augmented reality, and surveillance.
