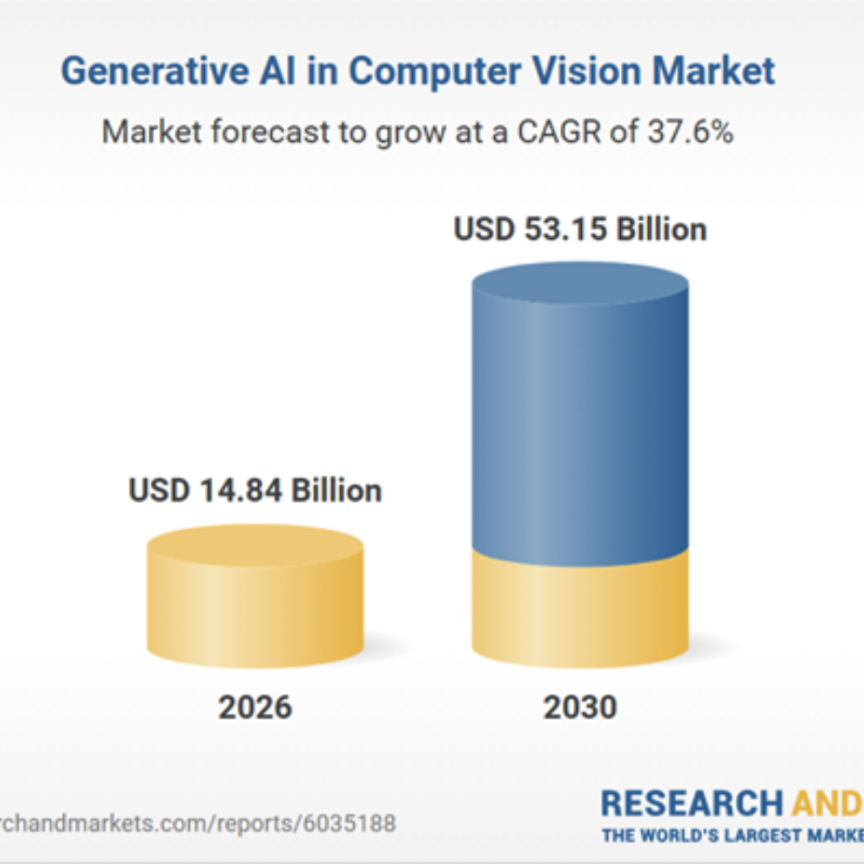
Vassilis Tsagaris and Dimitris Kastaniotis at Irida Labs say an iterative approach is needed to build a real-world AI vision application on embedded hardware
Deep learning models have been proven to achieve human levels of performance in many tasks and are nowadays the backbone of computer vision products. These models are very good at solving well-defined tasks with enough data, but in real-world applications it’s very unlikely that a task will have been defined from scratch.
Additionally, the computational capacity is bounded by hardware cost and power consumption, critical factors for mass deployment of products. Finally, decisions made by deep learning models are hard to interpret, and there is no mechanism to translate user experience into rules that would improve the model’s decisions according to the customer’s needs.
Computer vision is a powerful tool for products and services for daily life. Most of these applications are deployed on edge devices under the Internet of Things umbrella. However, IoT concepts are mostly designed to support the deployment of fixed functionalities like sensors, but not computer vision algorithms, which by default are entities that need to evolve over their lifetime.
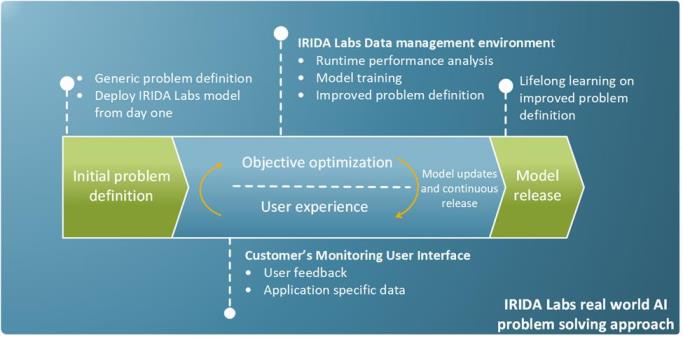
In order to close the gap between writing computer vision algorithms and deploying them on IoT devices, Irida Labs has developed an approach where user experience helps shape the end-product, including the model performance and the hardware selection.
User experience
A key concept of the Irida Labs approach is to rely on an agile development process that allows the customer to modify or adapt the definition of the task. Indeed, in most computer vision products, the customer tries to summarise the task in very abstract ways, like ‘people detection’. This description is usually followed by a small test set, which is not representative of the underlying data distribution of a real-world deployment. This is a weak definition of the task as it does not consider factors like the viewing angle, lighting, whether it’s deployed indoors or outside, and weather conditions.
In order to overcome this problem, the deployment of the device is connected to model development and, in particular, to data management and user experience. The main goal of this approach is to translate user experience into a representative test set. This is implemented by a software mechanism for receiving user feedback. The feedback comes from the real-world deployment of the first version of the model and allows the model to learn what samples are important. In this manner, Irida Labs provides a deep learning model that’s a good starting point, and then, together with the customer, iterates feedback to improve the model.
Data management and model development
The first version of the computer vision model uses data that matches the description of the task and the first test set of data. Subsequent releases, however, will require more application-specific data – the true challenge is in collecting the appropriate data.
The process of gathering data involves a number of mechanisms that can affect the model’s performance. For example, data sampling might introduce biases that are hard to detect. To overcome these pitfalls, Irida Labs uses a development process that incorporates some kind of intelligence and minimises human effort when it comes to annotating the data. This is achieved by implementing a data management engine, which includes data selection and curation, data augmentation, usually using machine learning techniques or synthetic data generation, and automatic labelling.
Model deployment and lifelong learning
Deploying the computer vision model is the most challenging aspect from a software and hardware architectural perspective. Models should be able to run on low-resource platforms; working with highly pruned machine learning models that operate with low-bit accuracy is the selection of choice for this hardware.
The model should also support functionalities that give it the ability to learn how to improve from data supplied for each unit, local area or solution-level using self-supervised learning. More specifically, the data distribution might shift significantly during the product lifetime; it can present periodic patterns related to winter or summer conditions, for instance. That’s why the model should be able to adapt to changes in data distribution to maintain accuracy. Also, the model needs to accept updates and provide an interface for user experience.
EV Lib workflow
The Irida Labs EV Lib workflow gives a solid task definition by iterating in model deployment and development. During this iteration Irida Labs is continuously translating the user experience from prototype installations in order to improve the data specifications and the performance of the model. The iteration stops when human-level performance is achieved, or when the customer specification and experience are met.
This approach allows Irida Labs to optimise the final solution in terms of model performance, hardware costs and achieve reduced time-to-market. At the same time, the approach provides a mechanism for support with updates and new features throughout the product life cycle.
Summarising the benefits of the EV Lib workflow, the customer will be guided through defining the task, acquiring the data and optimising the model, allowing both Irida Labs and the customer to focus on the main objective – delivering a real-world AI solution. Additionally, any changes made in the models over time are sent back to the client deployment environment by releasing new model versions.


Vassilis Tsagaris and Dimitris Kastaniotis. Irida Labs is a computer vision firm based in Patras, Greece. This article is based on a presentation Vassilis Tsagaris gave at the Embedded Vision Europe event in Stuttgart, Germany in October 2019.
Write for us
Want to write about an industrial imaging project where you have successfully deployed deep learning? Email: greg.blackman@europascience.com.