Prior to speaking at the Embedded World trade fair, The Khronos Group’s president, Neil Trevett, discusses the open API standards available for applications using machine learning and embedded vision
Technologists in the machine learning industry are finding new opportunities for deploying devices and applications that leverage neural network inferencing, now with unseen levels of vision-based functionality and accuracy. But with this rapid evolution comes a dense and confusing landscape of processors, accelerators, and libraries. This article assesses the role open interoperability standards play in reducing the costs and barriers to using inferencing and vision acceleration in real-world products.
Every industry needs open standards to reduce costs and time-to-market through increased interoperability between ecosystem elements. Open standards and proprietary technologies have complex and interdependent relationships. Proprietary APIs and interfaces are often the Darwinian testing ground and can remain dominant in the hands of a smart market leader, and that is as it should be. Strong open standards result from a wider need for a proven technology in the industry and can provide healthy, motivating competition. In the long view, an open standard that is not controlled by, or dependent on, any single company can often be the thread of continuity for progress as technologies, platforms and market positions swirl and evolve.
The Khronos Group is a non-profit standards consortium that is open for any company to join, with more than 150 members. All standards organisations exist to provide a safe place for competitors to cooperate for the good of all. The Khronos Group’s area of expertise is creating open, royalty-free API standards that enable software applications libraries and engines to harness the power of silicon acceleration for demanding use cases, such as 3D graphics, parallel computation, vision processing and inferencing.
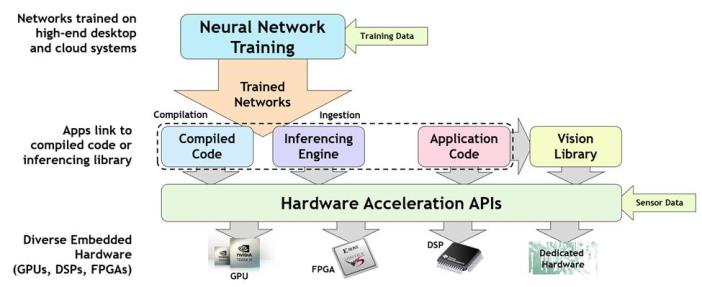
Steps in training neural networks and deploying them on accelerated inferencing platforms
Creating embedded machine learning applications
Many interoperating pieces need to work together to train a neural network and deploy it successfully on an embedded, accelerated inferencing platform. Effective neural network training typically takes large data sets, uses floating point precision and is run on powerful GPU-accelerated desktop machines or in the cloud. Once trained, the neural network is combined with an inferencing run-time engine optimised for fast tensor operations, or a machine learning compiler that transforms the neural network description into executable code. Whether an engine or compiler is used, the final step is to accelerate the inferencing code on one of a diverse range of accelerator architectures ranging from GPUs through to dedicated tensor processors.
So, how can industry open standards help streamline this process? The figure below illustrates Khronos standards that are being used in the field of vision and inferencing acceleration. In general, there is increasing interest in all these standards as processor frequency scaling gives way to parallel programming as the most effective way to deliver performance at acceptable levels of cost and power.
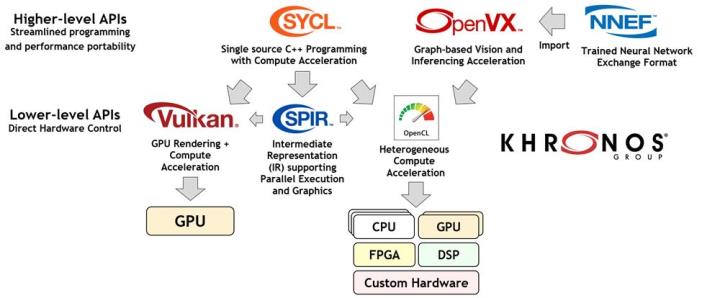
Khronos standards used in accelerating vision and inferencing applications and engines
Broadly, these standards can be divided into two groups: high-level and low-level. The high-level APIs focus on ease of programming with effective performance portability across multiple hardware architectures. In contrast, low-level APIs provide direct, explicit access to hardware resources for maximum flexibility and control. It is important that each project understand which level of API will best suit their development needs. Also, often the high-level APIs will use lower-level APIs in their implementation.
Let’s take a look at some of these Khronos standards in more detail.
SYCL: C++ single-source heterogeneous programming
SYCL (pronounced ‘sickle’) uses C++ template libraries to dispatch selected parts of a standard ISO C++ application to offload processors. SYCL enables complex C++ machine learning frameworks and libraries to be compiled and accelerated to performance levels that in many cases outperform hand-tuned code. By default, SYCL is implemented over the lower-level OpenCL standard API, feeding code for acceleration into OpenCL and the remaining host code through the system’s default CPU compiler.
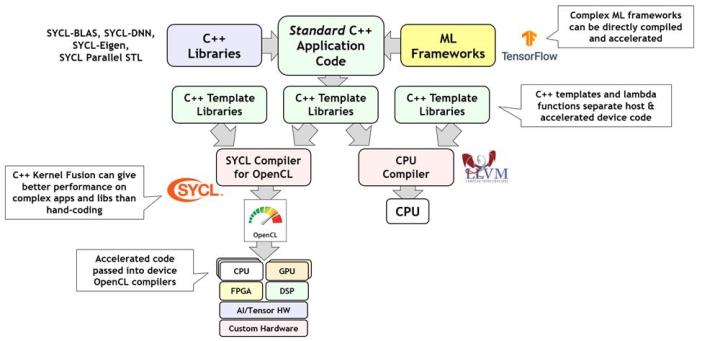
SYCL splits a standard C++ application into CPU and OpenCL-accelerated code
There are an increasing number of SYCL implementations, some of which use proprietary back-ends, such as Nvidia’s Cuda for accelerated code. Significantly, Intel’s new OneAPI initiative contains a parallel C++ compiler called DPC++ that is a conformant SYCL implementation over OpenCL.
Neural network exchange format
There are dozens of neural network training frameworks in use today including Torch, Caffe, TensorFlow, Theano, Chainer, Caffe2, PyTorch, MXNet and many more – and all use proprietary formats to describe their trained networks. There are also dozens, maybe even hundreds, of embedded inferencing processors hitting the market. Forcing that many hardware vendors to understand and import so many formats is a classic fragmentation problem that can be solved with an open standard.
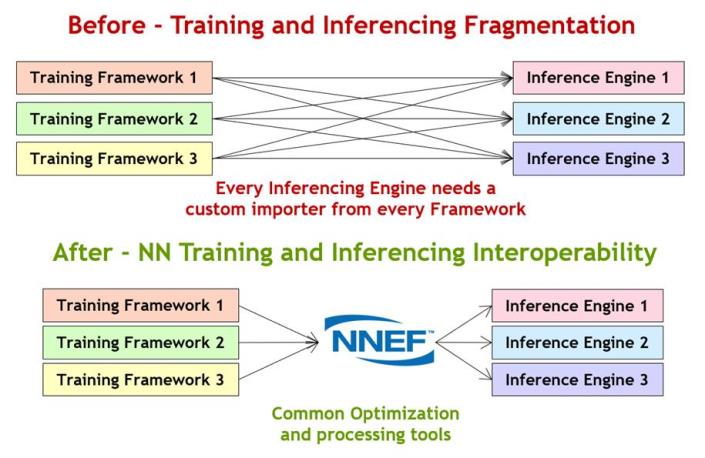
The neural network exchange format enables streamline ingestion of trained networks by inferencing accelerators
The neural network exchange format (NNEF) is targeted at providing an effective bridge between the worlds of network training and inferencing silicon. Khronos’ multi-company governance model gives the hardware community a strong voice on how the format evolves in a way that meets the needs of companies developing processor toolchains and frameworks, often in safety critical markets.
NNEF is not the industry’s only neural network exchange format; ONNX is an open source project founded by Facebook and Microsoft and is a widely adopted format that is primarily focused on the interchange of networks between training frameworks. NNEF and ONNX are complementary as ONNX tracks rapid changes in training innovations and the machine learning research community, while NNEF is targeted at embedded inferencing hardware vendors that need a format with a more considered roadmap evolution. Khronos has initiated a growing open source tools ecosystem around NNEF, including importers and exporters from key frameworks and a model zoo to enable hardware developers to test their inferencing solutions.
OpenVX: portable accelerated vision processing
OpenVX (VX stands for ‘vision acceleration’) streamlines the development of vision and inferencing software by providing a graph-level abstraction that enables a programmer to construct their required functionality through connecting a set of functions or ‘nodes’. This high-level of abstraction enables silicon vendors to optimise their OpenVX drivers for efficient execution on almost any processor architecture. Over time, OpenVX has added inferencing functionality alongside the original vision nodes – neural networks are just another graph after all! There is growing synergy between OpenVX and NNEF through the direct import of NNEF trained networks into OpenVX graphs.
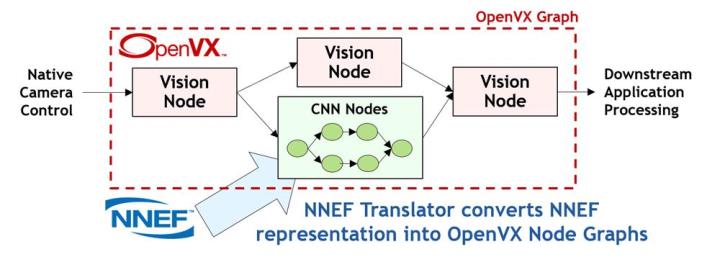
An OpenVX graph can describe any combination of vision nodes and inferencing operations imported from an NNEF file
OpenVX 1.3 was released in October 2019. Users can take selected subsets of the specification targeted at vertical market segments, such as inferencing, and implement and test them as officially conformant. OpenVX also has a deep integration with OpenCL so that a programmer can add their own custom accelerated nodes for use within an OpenVX graph – providing a combination of easy programmability and customisability.
OpenCL: heterogeneous parallel programming
OpenCL is a low-level standard for cross-platform parallel programming of diverse heterogeneous processors found in PC, servers, mobile devices and embedded devices. OpenCL provides C and C++-based languages for constructing kernel programs that can be compiled and executed in parallel across any processors in a system with an OpenCL compiler, giving explicit control over which kernels are executed on which processors to the programmer. The OpenCL run-time coordinates the discovery of accelerator devices, compiles kernels for selected devices, executes the kernels with sophisticated levels of synchronisation, and gathers the results.
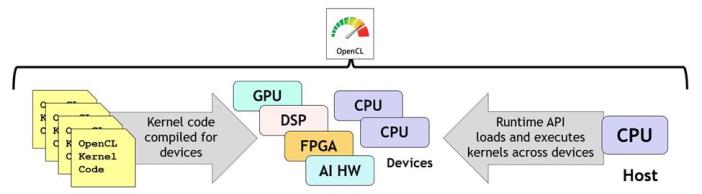
OpenCL enables C or C++ kernel programs to be compiled and executed in parallel across any combination of heterogeneous processors
OpenCL is used pervasively throughout the industry for providing the lowest ‘close-to-metal’ execution layer for compute, vision and machine learning libraries, engines and compilers.
OpenCL was originally designed for execution on high-end PC and supercomputer hardware, but in a similar evolution to OpenVX, processors needing OpenCL are getting smaller, with less precision, as they target edge vision and inferencing. The OpenCL working group is working to define functionality tailored to embedded processors and to enable vendors to ship selected functionality targeted at key power- and cost-sensitive use cases with full conformance.
Get involved
As the ecosystem for programming and deploying accelerated vision and inferencing software continues to evolve, Khronos remains committed to playing a vital role by providing a safe space for companies to cooperate to create open standards that benefit their own business and the wider industry. If your own company would like a voice and vote in any of these standardisation activities, or you wish to implement a Khronos standard on your silicon, Khronos warmly welcomes any company that wishes to participate – we look forward to hearing from you!
About the author
Neil Trevett is vice president of developer ecosystems at Nvidia. He is also the elected president of the Khronos Group, where he initiated the OpenGL ES standard, fostered the creation of the OpenVX standard, and chairs the OpenCL working group. He will give a presentation about this topic at Embedded World in Nuremberg, Germany on 27 February during the embedded vision session. ntrevett@nvidia.com; www.khronos.org
Write for us
Are you using any of these standards? Want to write about an industrial imaging project where you have successfully deployed inferencing or embedded vision? Email: greg.blackman@europascience.com.