
Jeff Bier, founder of the Embedded Vision Alliance, discusses the four key trends driving the proliferation of visual perception in machines
We started the Embedded Vision Alliance in 2011 because we believed that there would soon be unprecedented growth in investment, innovation and deployment of practical computer vision technology across a broad range of markets. Less than a decade later, our expectation has been fulfilled. For example, data presented by Woodside Capital at the 2018 Embedded Vision Summit documents 100-times growth in USA- and China-based vision companies over the past six years. These investments – and others not reflected in this data, such as investments taking place in other countries and companies’ internal investments – are enabling companies to rapidly accelerate their vision-related research, development and deployment activities.
To help understand technology choices and trends in the development of vision-based systems, devices and applications, the Embedded Vision Alliance conducts an annual survey of product developers. The most recent was completed in November; 93 per cent of respondents reported that they expect an increase in their organisation’s vision-related activity over the coming year (61 per cent expect a large increase). Of course, these companies expect their increasing development investments to translate into increased revenue. Market researchers agree. Tractica research forecasts a 25-times increase in revenue for computer vision hardware, software and services between now and 2025, reaching $26 billion.
Three fundamental factors are driving the accelerating proliferation of visual perception: first, it works well enough for diverse, real-world applications; second, it can be deployed at low cost, with low power consumption; and it’s increasingly usable by non-specialists. In addition, four key trends underlie these factors: deep learning; 3D perception; fast, inexpensive, energy-efficient processors; and the democratisation of hardware and software.
Deep learning
Traditionally, computer vision applications have relied on highly specialised algorithms painstakingly designed for each specific application and use case. In contrast to traditional algorithms, deep learning uses generalised learning algorithms, which are trained through examples. Deep neural networks (DNNs) have transformed computer vision, delivering superior results on tasks such as recognising objects, localising objects in a frame and determining which pixels belong to which object. Even problems previously considered ‘solved’ with conventional techniques are now finding better solutions using deep learning.
As a result, computer vision developers are adopting deep learning techniques. In the Alliance’s most recent survey, 59 per cent of vision system developers are using DNNs (an increase from 34 per cent two years ago). Another 28 per cent are planning to use DNNs for visual intelligence in the near future.
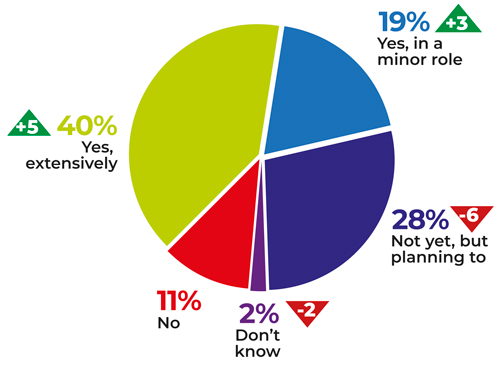
Results from the Embedded Vision Alliance's computer vision developer survey in November 2018. Triangles indicate percentage change from November 2017
3D perception
The 2D image sensors found in many vision systems enable a tremendous breadth of vision capabilities. But adding depth information can be extremely valuable. For example, for a gesture-based user interface, the ability to discern not only lateral motion, but also motion perpendicular to the sensor, greatly expands the variety of gestures that a system can recognise.
In other applications, depth information enhances accuracy. In face recognition, for example, depth sensing is valuable in determining that the object being sensed is an actual face, versus a photograph. And the value of depth information is obvious in moving systems, such as mobile robots and automobiles.
Historically, depth sensing has been an exotic, expensive technology, but this has changed dramatically. The use of optical depth sensors in the Microsoft Kinect, and more recently in mobile phones, has catalysed a rapid acceleration in innovation, resulting in depth sensors that are tiny, inexpensive and energy-efficient.
This change has not been lost on system developers. Thirty four per cent of developers participating in the Alliance’s most recent survey are already using depth perception, with another 29 per cent (up from 21 per cent a year ago) planning to incorporate depth in upcoming projects across a range of industries.
Fast, inexpensive, energy-efficient processors
Arguably, the most important ingredient driving the widespread deployment of visual perception is better processors. Vision algorithms typically have huge appetites for computing performance. Achieving the required levels of performance with acceptable cost and power consumption is a common challenge, particularly as vision is deployed into cost-sensitive and battery-powered devices.
Fortunately, in the past few years there’s been an explosion in the development of processors tuned for computer vision. These purpose-built processors are coming to market, delivering huge improvements in performance, cost, energy efficiency and ease of development.
Progress in efficient processors has been boosted by the growing adoption of deep learning for two reasons. First, deep learning algorithms tend to require even more processing performance than conventional computer vision algorithms, amplifying the need for more efficient processors. Second, the most widely used deep learning algorithms share many common characteristics, which simplifies the task of designing a specialised processor intended to execute these algorithms very efficiently.
Today, typically, computer vision algorithms use a combination of a general-purpose CPU and a specialised parallel co-processor. Historically, GPUs have been the most popular type of co-processor, because they were widely available and supported with good programming tools. These days, there’s a much wider range of co-processor options, with newer types of co-processors typically offering significantly better efficiency. The trade-off is that these newer processors are less widely available, less familiar to developers and not yet as well supported by mature development tools.
According to the most recent Embedded Vision Alliance developer survey, nearly one-third of respondents are using deep learning-specific co-processors. This is remarkable, considering that deep learning-specific processors didn’t exist a few years ago.
Democratisation of computer vision
By ‘democratisation’, we mean that it’s becoming much easier to develop computer vision-based algorithms, systems and applications, as well as to deploy these solutions at scale – enabling many more developers and organisations to incorporate vision into their systems. What is driving this trend? One answer is the rise of deep learning. Because of the generality of deep learning algorithms, with deep learning there’s less of a need to develop specialised algorithms. Instead, developer focus can shift to selecting among available algorithms, and then to obtaining the necessary quantities of training data.
Another critical factor is the rise of cloud computing. For example, rather than spending days or weeks installing and configuring development tools, today engineers can get instant access to pre-configured development environments in the cloud. Likewise, when large amounts of compute power are required to train or validate a neural network algorithm, this power can be quickly and economically obtained in the cloud. And cloud computing offers an easy path for initial deployment of many vision-based systems, even in cases where ultimately developers will switch to edge-based computing, for example to reduce costs.
November’s Embedded Vision Alliance developer survey found 75 per cent of respondents using deep neural networks for visual understanding in their products deploy those neural networks at the edge, while 42 per cent use the cloud. (These figures total to more than 100 per cent because some survey respondents use both approaches.)
The Embedded Vision Summit
The world of practical computer vision is changing very fast, opening up many exciting technical and business opportunities. An excellent way to learn about the latest developments in practical computer vision is to attend the Embedded Vision Summit, taking place 20 to 23 May in Santa Clara, California. It attracts a global audience of more than 1,000 product creators, entrepreneurs and business decision-makers who are developing and using computer vision technology. It has experienced exciting growth over the last few years, with 97 per cent of 2018 attendees reporting they would recommend the event to a colleague. The summit is the place to learn about the latest applications, techniques, technologies and opportunities in visual AI and deep learning. Online registration is at www.embedded-vision.com/summit/register. Use the code SUMMIT19IMVE for a discount. See you there!
--
Visionary products at Embedded World
Machine vision firms will be displaying the latest hardware and software for embedded system developers at the Embedded World trade fair, from 26 to 28 February in Nuremberg, Germany.
Alongside the technology in the exhibition halls, the Embedded World conference will run a track on embedded vision on 26 February, organised in collaboration with the VDMA. Presentations include those from Arm; AllGo Systems on implementing a camera-based driver monitoring system; Intel on developing a multi-platform computer vision solution and on enhancing human vision; Allied Vision; NXP Semiconductors on machine learning for embedded vision; MVTec Software; and Synopsys on SLAM for augmented reality. There will also be a panel discussion on embedded vision on 27 February from 10.30 to 11.30am at the Forum in hall two.
Industrial vision companies including Allied Vision (3A-418), Basler (2-550), Framos (3A-749), Imago Technologies (1-458), MVTec Software (4-203) and Vision Components (2-444), will be among the exhibitors on the trade fair floor.
Framos recently introduced a product line of sensor modules, and module and processor adapters. Different processors and platforms, such as Nvidia’s Jetson or Qualcomm’s DragonBoard, will be on display to demonstrate the flexibility in design available to engineers.

Framos will show its SLVS-EC Rx IP core for Xilinx FPGAs, which can be used with SLVS-EC-based sensors. Century Arks will show a system with six camera modules developed for Internet of Things (IoT)-based 360° devices. The modules include the Sony IMX378 sensor, a focusable lens and image stabilisation.
Basler will present its development kits, which support various embedded platforms. It will have live demonstrations on topics including IoT, AI and face detection.
MVTec Software will focus on its latest software releases, Halcon 18.11 and Merlic 4. The company will have a multi-platform live demonstration on its booth, where four embedded boards will perform different tasks using Halcon and Merlic. In another demo, MVTec will present four standard examples of deep learning machine vision technologies in parallel – semantic segmentation, object detection, classification and optical character recognition – all run on an Nvidia Xavier board.
Imago Technologies will show its VisionCam Prophesee, a Linux-based smart camera able to analyse fast moving scenes. Also on display will be the VisionCam Line Scan, a complete line scan system containing a multi-core Arm CPU that uses the Halcon image processing library.

Vision Components has released ambient light suppression technology in its VCnano3D-Z laser profilers. The scanners use a class two, 450nm laser, and are suitable for inspecting metallic surfaces. They contain a Xilinx Zynq SoC, of which the FPGA has been programmed to calculate the 3D point cloud, leaving the 2 x 866MHz Arm processor a freely programmable resource to handle application-specific machine vision tasks. The profilers can therefore also be programmed to analyse a greyscale image.
Elsewhere, Irida Labs (3A-549) will display its EVLib, a deep learning-based software library. The software consists of CNN models optimised to power AI on edge devices such as cameras, IoT devices and embedded CPUs. The software has more than 100 learning models that are pre-trained for accuracy, speed and low power performance. The runtime models are optimised for Arm-based CPU platforms or GPU acceleration. Library functions include: people or vehicle detection and counting; soft biometrics; and 2D/3D object detection and tracking.
Irida Labs will also have a smart parking demo on its partner booths, Arrow (4A-340) and Analog Devices (4A-641), while a tool for visually inspecting a shopping basket to detect and count different products will be shown on the booths of NXP (4A-220), Basler (2-550) and Congatec (1-358). Critical Link (4-180) will showcase its MitySOM-A10S system-on-module, designed with the Intel/Altera Arria 10 SoC. In addition to the processor, the module includes on-board power supplies, two DDR4 RAM memory subsystems, micro SD card, a USB 2.0 port and a temperature sensor.
Entner Electronics (3-748) will display its UC-310 and UC-200 cameras, which both have zoom capability and run an Arm processor. Entner will also release two small form factor Flex video processing modules, for building vision solutions with multiple cameras. The boards use a video processor with 3D and 4K support.

Finally, frame grabbers from Active Silicon will be presented by ADL Embedded Solutions (1-554) and EKF Elektronik (1-660). On ADL’s booth, Active Silicon’s Phoenix PCI/104e Camera Link frame grabber and FireBird Quad USB 3.0 host controller will be on display, while alongside EKF’s industrial computers will be Active Silicon’s FireBird Camera Link 3U cPCI Serial frame grabber. Active Silicon frame grabbers include ActiveDMA technology, which transfers data directly to PC memory without any host CPU intervention.
Other industrial smart cameras that have been released recently but won’t be at Embedded World, include: the Predator from Cretec, a smart camera with an aluminium housing that developers can port their own code into; and Automation Technology’s IRSX series of smart infrared cameras, which combine a calibrated thermal image sensor with a data processing unit and a variety of industrial interfaces.
--
![]()
MATRIX VISION: Featured product
The mvBlueGEMINI smart camera is an ideal camera for beginners and experienced image processors alike, thanks to the new “mvIMPACT Configuration Studio” software. The mvIMPACT-CS software is web-based and, therefore, offers a range of advantages: it does not need to be installed and can be accessed from a variety of devices, such as tablets, smartphones and PCs, simultaneously over a network or via an available WLAN access point. Wizards provide intuitive user guidance, and parameters have been reduced to just those that are absolutely necessary, supporting the user, and as a result accelerating the development of the application. In addition, the software can be trained to carry out tasks, for which mvIMPACT-CS selects the required algorithms and sets the appropriate parameters. This means that knowledge of image processing techniques is not necessarily required.

www.matrix-vision.com/smart-cam-compact-application-camera.html
